
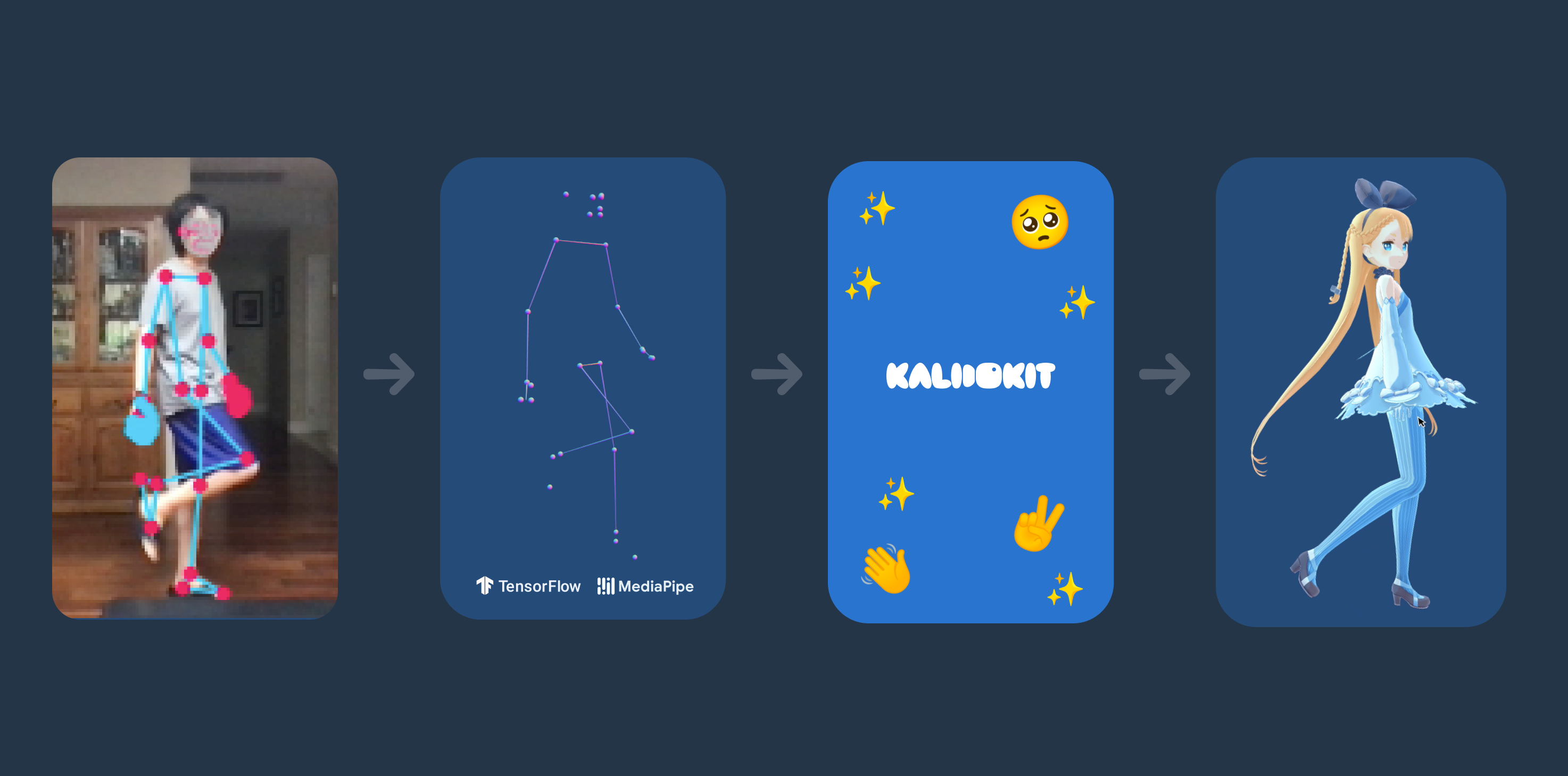
KalidoKit is the integration of a variety of algorithms to achieve, Facemesh, Blazepose, Handpose, Holistic. Let’s see the effect.
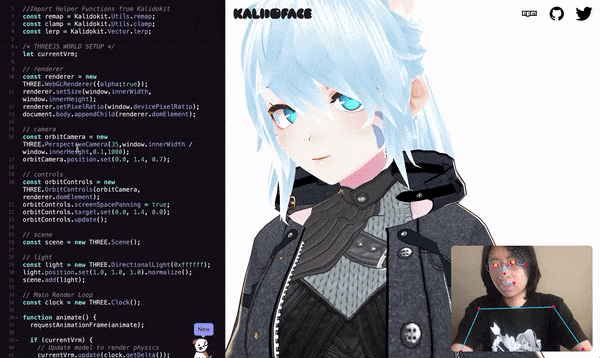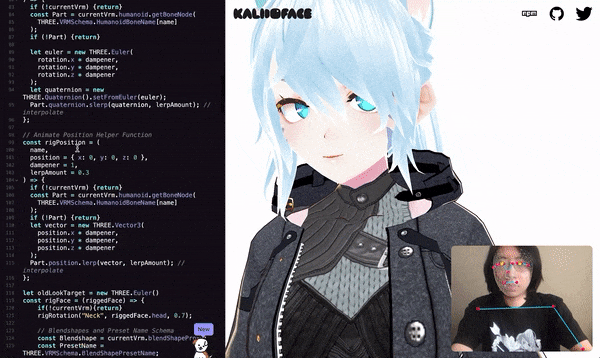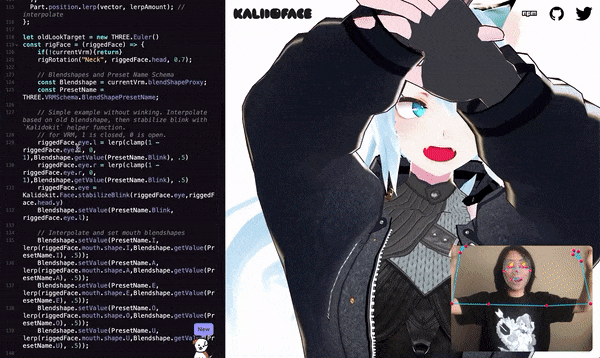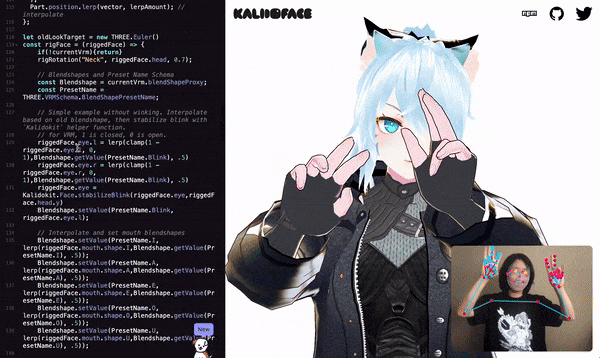
The virtual image is driven by the movements of real human limbs, faces and hands.
The mainstream application direction of this technology is virtual anchor.
It is possible to drive avatars to dance.

It can also capture the whole body movements, facial expressions, gestures, etc., like the motion picture at the beginning.
In addition to this type of driving virtual image type, you can also use your imagination to make some interesting small applications.

KalidoKit
This project is based on Tensorflow.js implementation.
Project address: https://github.com/yeemachine/kalidokit
The key point information captured can be used to drive 2D and 3D avatars, combined with some avatar driving engines, to achieve the effect shown at the beginning of the article.
It is possible to drive both Live2D images and 3D VRM images.
The technical points involved here can’t be finished in one article, so today we mainly talk about the basic key point detection technologies: face key point detection, human pose estimation, and gesture pose estimation.
Face keypoint detection
Face keypoint detection, there are sparse and dense.
Like the basic one, 68 keypoints are detected.

Generally speaking, for the detection of closed eyes, head posture, open and closed mouth, a simple 68 keypoints is enough.
Of course, there are also more dense keypoints detection.

For some skin beauty applications, a dense keypoint detection algorithm is needed, with thousands of keypoints.
But the idea of the algorithm is the same, to return the location coordinates of these keypoints, usually used with face detection algorithms.
For those who want to learn face keypoint detection algorithms, we recommend two introductory projects.
One is a basic introductory project, and the other integrates the mainstream algorithms for face keypoints.
Human Pose Estimation
Human pose estimation is also a very basic problem in computer vision.
From the point of view of the name, it can be understood as the estimation of the position of the “human body” pose (key points, such as head, left hand, right foot, etc.).
Generally, there are 4 types of tasks.
- Single-Person Skeleton Estimation (SPSE)
- Multi-person Pose Estimation
- Video Pose Tracking
- 3D Skeleton Estimation
Simply put, it is the detection of human skeleton joint points to locate the human pose.
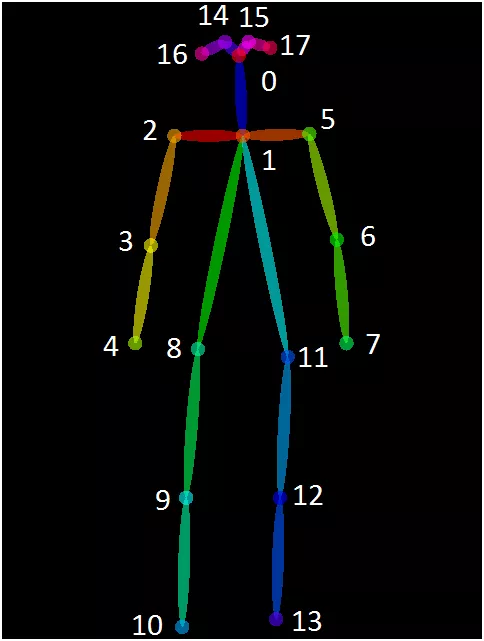
Human pose estimation has a wide range of applications, for example, pose detection and action prediction of pedestrians in street scenes in the autonomous driving industry; pedestrian re-identification problems in the security field, specific action monitoring in special scenes; movie special effects in the film industry, etc.
For those who want to learn, you can read this compiled paper at:
Gestural posture estimation
Hand joints are more flexible, agile and self-obscuring, so it is a little more complicated.
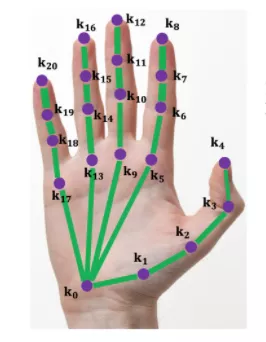
But the principle is similar to human posture estimation.

In addition to this regular gesture recognition, it can also be used to do some special effects.

In fact, many of these human effects, the positioning of the position, are achieved with the help of these key points.
As above, to learn, you can see this integrated material at: